Experiments#
Overview#
SmartSim helps automate the deployment of AI-enabled workflows on HPC systems. With SmartSim, users can describe and launch combinations of applications and AI/ML infrastructure to produce novel and scalable workflows. SmartSim supports launching these workflows on a diverse set of systems, including local environments such as Mac or Linux, as well as HPC job schedulers (e.g. Slurm, PBS Pro, and LSF).
The Experiment API is SmartSim’s top level API that provides users with methods for creating, combining,
configuring, launching and monitoring entities in an AI-enabled workflow. More specifically, the
Experiment API offers three customizable workflow components that are created and initialized via factory
methods:
Settings are given to Model and Ensemble objects to provide parameters for how the job should be executed. The
Experiment API offers two customizable Settings objects that are created via the factory methods:
Once a workflow component is initialized (e.g. Orchestrator, Model or Ensemble), a user has access
to the associated entity API which supports configuring and retrieving the entities’ information:
There is no limit to the number of SmartSim entities a user can
initialize within an Experiment.
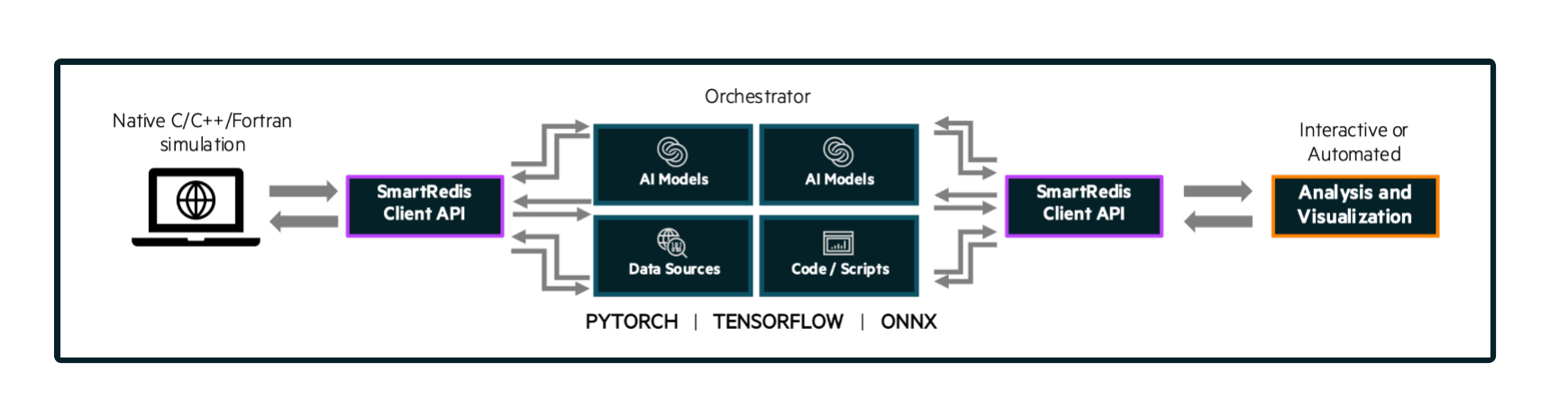
Sample Experiment showing a user application leveraging
machine learning infrastructure launched by SmartSim and connected
to online analysis and visualization via the in-memory Orchestrator.#
Find an example of the Experiment class and factory methods used within a
workflow in the Example section of this page.
Launchers#
SmartSim supports launching AI-enabled workflows on a wide variety of systems, including locally on a Mac or
Linux machine or on HPC machines with a job scheduler (e.g. Slurm, PBS Pro, and LSF). When creating a SmartSim
Experiment, the user has the opportunity to specify the launcher type or defer to automatic launcher selection.
Launcher selection determines how SmartSim translates entity configurations into system calls to launch,
manage, and monitor. Currently, SmartSim supports 7 launcher options:
local[default]: for single-node, workstation, or laptopslurm: for systems using the Slurm schedulerpbs: for systems using the PBS Pro schedulerpals: for systems using the PALS schedulerlsf: for systems using the LSF schedulerdragon: if Dragon is installed in the current Python environment, see Dragon Installauto: have SmartSim auto-detect the launcher to use (will not detectdragon)
The Dragon-based launcher can be run on PBS- or Slurm-based systems (MPI applications are supported only when Cray PMI or Cray PALS are available).
If the systems launcher cannot be found or no launcher argument is provided, the default value of
“local” will be assigned which will start all Experiment launched entities on the
localhost.
For examples specifying a launcher during Experiment initialization, navigate to the
Experiment __init__ special method in the Experiment API docstring.
Entities#
Entities are SmartSim API objects that can be launched and
managed on the compute system through the Experiment API.
The SmartSim entities include:
OrchestratorModelEnsemble
While the Experiment object is intended to be instantiated once in the
Python driver script, there is no limit to the number of SmartSim entities
within the Experiment. In the following subsections, we define the
general purpose of the three entities that can be created through the
Experiment.
To create a reference to a newly instantiated entity object, use the
associated Experiment.create_... factory method shown below.
Factory Method |
Example |
Return Type |
|---|---|---|
|
|
|
|
|
|
|
|
After initialization, each entity can be started, monitored, and stopped using
the Experiment post-creation methods.
Factory Method |
Example |
Desc |
|---|---|---|
|
|
Launch an Entity |
|
|
Stop an Entity |
|
|
Retrieve Entity Status |
|
|
Preview an Entity |
Orchestrator#
The Orchestrator is an in-memory database built for
a wide variety of AI-enabled workflows. The Orchestrator can be thought of as a general
feature store for numerical data, ML models, and scripts. The Orchestrator is capable
of performing inference and script evaluation using data in the feature store.
Any SmartSim Model or Ensemble member can connect to the
Orchestrator via the SmartRedis
Client library to transmit data, execute ML models, and execute scripts.
SmartSim Offers Two Types of Orchestrator Deployments:
To create a standalone Orchestrator that does not share compute resources with other
SmartSim entities, use the Experiment.create_database factory method which
returns an Orchestrator object. To create a colocated Orchestrator that
shares compute resources with a Model, use the Model.colocate_db_tcp
or Model.colocate_db_uds member functions accessible after a
Model object has been initialized. The functions instruct
SmartSim to launch an Orchestrator on the application compute nodes. An Orchestrator object is not
returned from a Model.colocate_db instruction, and subsequent interactions with the
colocated Orchestrator are handled through the Model API.
SmartSim supports multi-database functionality, enabling an Experiment to have
several concurrently launched Orchestrator(s). If there is a need to launch more than
one Orchestrator, the Experiment.create_database and Model.colocate..
functions mandate the specification of a unique Orchestrator identifier, denoted
by the db_identifier argument for each Orchestrator. The db_identifier is used
in an application script by a SmartRedis Client to connect to a specific Orchestrator.
Model#
Model(s) represent a simulation model or any computational kernel,
including applications, scripts, or generally, a program. They can
interact with other SmartSim entities via data transmitted to/from
SmartSim Orchestrator(s) using a SmartRedis Client.
A Model is created through the factory method: Experiment.create_model.
Model(s) are initialized with RunSettings objects that specify
how a Model should be launched by a workload manager
(e.g., Slurm) and the compute resources required.
Optionally, the user may also specify a BatchSettings object if
the Model should be launched as a batch job on the WLM system.
The create_model factory method returns an initialized Model object that
gives you access to functions associated with the Model API.
A Model supports key features, including methods to:
Attach configuration files for use at
Modelruntime.Colocate an Orchestrator to a SmartSim
Model.Load an ML model into the
OrchestratoratModelruntime.Load a TorchScript function into the
OrchestratoratModelruntime.Enable data collision prevention which allows for reuse of key names in different
Modelapplications.
Visit the respective links for more information on each topic.
Ensemble#
In addition to a single Model, SmartSim allows users to create,
configure, and launch an Ensemble of Model objects.
Ensemble(s) can be given parameters and a permutation strategy that define how the
Ensemble will create the underlying Model objects. Users may also
manually create and append Model(s) to an Ensemble. For information
and examples on Ensemble creation strategies, visit the Initialization
section within the Ensemble documentation.
An Ensemble supports key features, including methods to:
Attach configuration files for use at
Ensembleruntime.Load an ML model (TF, TF-lite, PT, or ONNX) into the
OrchestratoratEnsembleruntime.Load a TorchScript function into the
OrchestratoratEnsembleruntime.Prevent data collisions within the
Ensemble, which allows for reuse of application code.
Visit the respective links for more information on each topic.
File Structure#
When a user executes an Experiment script, it generates output folders in the system’s directory.
By default, SmartSim creates a predefined file structure and assigns a path to each entity initialized.
However, users have the flexibility to customize this according to workflow needs. Please refer
to the respective default and configure sections below
for more details.
Note
Files added for symlinking, copying, or configuration will not be organized into the generated
directories unless Experiment.generate is invoked on the designated entity.
Default#
By default, an Experiment folder is created in your current working directory, using the
specified name parameter during Experiment initialization. Each entity created by the
Experiment generates an output folder under the Experiment directory, named after the
entity. These folders hold .err and .out files, containing execution-related information.
For instance, consider the following Python script:
from smartsim import Experiment
exp = Experiment(name="experiment-example")
database = exp.create_database(port=6379, interface="ib0")
exp.start(database)
settings = exp.create_run_settings(exe="echo", exec_args="hello world")
model = exp.create_model(name="model-name", run_settings=settings)
ensemble = exp.create_ensemble(name="ensemble-name", run_settings=settings, replicas=2)
exp.start(model, ensemble)
exp.stop(database)
When executed, this script creates the following directory structure in your working directory:
experiment-example
├── orchestrator
│ ├── orchestrator_0.err
│ └── orchestrator_0.out
├── model-name
│ ├── model-name.err
│ └── model-name.out
└── ensemble-name
├── ensemble-name_0
│ ├── ensemble-name_0.err
│ └── ensemble-name_0.out
├── ensemble-name_1
│ ├── ensemble-name_1.err
│ └── ensemble-name_1.out
Configure#
Customizing the path of the Experiment and entity folders is possible by providing
either an absolute or relative path to the path argument during initialization. When
a relative path is provided, SmartSim executes the entity relative to the current working
directory.
For instance, consider the following Python script:
from smartsim import Experiment
exp = Experiment(name="experiment-example", exp_path="absolute/path/to/experiment-folder")
database = exp.create_database(port=6379, interface="ib0")
exp.start(database)
settings = exp.create_run_settings(exe="echo", exec_args="hello world")
model = exp.create_model(name="model-name", run_settings=settings, path="./model-folder")
ensemble = exp.create_ensemble(name="ensemble-name", run_settings=settings, replicas=2, path="./ensemble-folder")
exp.start(model, ensemble)
exp.stop(database)
When executed, this script creates the following directory structure in your working directory:
├── experiment-folder
| ├── orchestrator
| │ ├── orchestrator_0.err
| │ └── orchestrator_0.out
├── model-folder
│ ├── model-name.err
│ └── model-name.out
└── ensemble-folder
├── ensemble-name_0
│ ├── ensemble-name_0.err
│ └── ensemble-name_0.out
├── ensemble-name_1
│ ├── ensemble-name_1.err
│ └── ensemble-name_1.out
Example#
In the following section, we provide an example of using SmartSim to automate the
deployment of an HPC workflow consisting of a Model and standalone Orchestrator.
The example demonstrates:
- Initializing
a workflow (
Experiment)an in-memory database (standalone
Orchestrator)an application (
Model)
- Generating
the
Orchestratoroutput directorythe
Modeloutput directory
- Previewing
the
Orchestratorcontentsthe
Modelcontents
- Starting
an in-memory database (standalone
Orchestrator)an application (
Model)
- Stopping
an in-memory database (standalone
Orchestrator)
The example source code is available in the dropdown below for convenient execution and customization.
Example Driver Script Source Code
from smartsim import Experiment
from smartsim._core.control.previewrenderer import Verbosity
from smartsim.log import get_logger
# Initialize an Experiment
exp = Experiment("example-experiment", launcher="auto")
# Initialize a SmartSim logger
smartsim_logger = get_logger("logger")
# Initialize an Orchestrator
standalone_database = exp.create_database(db_nodes=3, port=6379, interface="ib0")
# Initialize the Model RunSettings
settings = exp.create_run_settings("echo", exe_args="Hello World")
# Initialize the Model
model = exp.create_model("hello_world", settings)
# Generate the output directory
exp.generate(standalone_database, model, overwrite=True)
# Preview the experiment
exp.preview(standalone_database, model, verbosity_level=Verbosity.DEBUG)
# Launch the Orchestrator then Model instance
exp.start(standalone_database, model)
# Clobber the Orchestrator
exp.stop(standalone_database)
# Log the summary of the Experiment
smartsim_logger.info(exp.summary())
Initializing#
To create a workflow, initialize an Experiment object
at the start of the Python driver script. This involves specifying
a name and the system launcher that will execute all entities.
Set the launcher argument to auto to instruct SmartSim to attempt
to find the machines WLM.
1from smartsim import Experiment
2from smartsim._core.control.previewrenderer import Verbosity
3from smartsim.log import get_logger
4
5# Initialize an Experiment
6exp = Experiment("example-experiment", launcher="auto")
7# Initialize a SmartSim logger
8smartsim_logger = get_logger("logger")
We also initialize a SmartSim logger. We will use the logger to log the Experiment
summary.
Next, launch an in-memory database, referred to as an Orchestrator.
To initialize an Orchestrator object, use the Experiment.create_database
factory method. Create a multi-sharded Orchestrator by setting the argument db_nodes to three.
SmartSim will assign a port to the Orchestrator and attempt to detect your machine’s
network interface if not provided.
1# Initialize an Orchestrator
2standalone_database = exp.create_database(db_nodes=3, port=6379, interface="ib0")
Before invoking the factory method to create a Model,
first create a RunSettings object. RunSettings hold the
information needed to execute the Model on the machine. The RunSettings
object is initialized using the Experiment.create_run_settings method.
Specify the executable to run and arguments to pass to the executable.
The example Model is a simple Hello World program
that echos Hello World to stdout.
1# Initialize the Model RunSettings
2settings = exp.create_run_settings("echo", exe_args="Hello World")
After creating the RunSettings object, initialize the Model object by passing the name
and settings to create_model.
1# Initialize the Model
2model = exp.create_model("hello_world", settings)
Generating#
Next we generate the file structure for the Experiment. A call to Experiment.generate
instructs SmartSim to create directories within the Experiment folder for each instance passed in.
We organize the Orchestrator and Model output files within the Experiment folder by
passing the Orchestrator and Model instances to exp.generate:
1# Generate the output directory
2exp.generate(standalone_database, model, overwrite=True)
Overwrite=True instructs SmartSim to overwrite entity contents if files and subdirectories
already exist within the Experiment directory.
Note
If files or folders are attached to a Model or Ensemble members through Model.attach_generator_files
or Ensemble.attach_generator_files, the attached files or directories will be symlinked, copied, or configured and
written into the created directory for that instance.
The Experiment.generate call places the .err and .out log files in the entity
subdirectories within the main Experiment directory.
Previewing#
Optionally, users can preview an Experiment entity. The Experiment.preview method displays the entity summaries during runtime
to offer additional insight into the launch details. Any instance of a Model, Ensemble, or Orchestrator created by the
Experiment can be passed as an argument to the preview method. Additionally, users may specify the name of a file to write preview data to
via the output_filename argument, as well as the text format through the output_format argument. Users can also specify how verbose
the preview is via the verbosity_level argument.
The following options are available when configuring preview:
verbosity_level=”info” instructs preview to display user-defined fields and entities.
verbosity_level=”debug” instructs preview to display user-defined field and entities and auto-generated fields.
verbosity_level=”developer” instructs preview to display user-defined field and entities, auto-generated fields, and run commands.
output_format=”plain_text” sets the output format. The only accepted output format is ‘plain_text’.
output_filename=”test_name.txt” specifies name of file and extension to write preview data to. If no output filename is set, the preview will be output to stdout.
In the example below, we preview the Orchestrator and Model entities by passing their instances to Experiment.preview:
1# Preview the experiment
2exp.preview(standalone_database, model, verbosity_level=Verbosity.DEBUG)
When executed, the preview logs the following in stdout:
=== Experiment Overview ===
Experiment Name: example-experiment
Experiment Path: absolute/path/to/SmartSim/example-experiment
Launcher: local
=== Entity Preview ===
== Orchestrators ==
= Database Identifier: orchestrator =
Path: absolute/path/to/SmartSim/example-experiment/orchestrator
Shards: 1
TCP/IP Port(s):
6379
Network Interface: ib0
Type: redis
Executable: absolute/path/to/SmartSim/smartsim/_core/bin/redis-server
== Models ==
= Model Name: hello_world =
Path: absolute/path/to/SmartSim/example-experiment/hello_world
Executable: /bin/echo
Executable Arguments:
Hello
World
Client Configuration:
Database Identifier: orchestrator
Database Backend: redis
TCP/IP Port(s):
6379
Type: Standalone
Outgoing Key Collision Prevention (Key Prefixing):
Tensors: Off
Datasets: Off
ML Models/Torch Scripts: Off
Aggregation Lists: Off
Starting#
Next launch the components of the Experiment (Orchestrator and Model).
To do so, use the Experiment.start factory method and pass in the previous
Orchestrator and Model instances.
1# Launch the Orchestrator then Model instance
2exp.start(standalone_database, model)
Stopping#
Lastly, to clean up the Experiment, tear down the launched Orchestrator
using the Experiment.stop factory method.
1# Clobber the Orchestrator
2exp.stop(standalone_database)
Notice that we use the Experiment.summary function to print
the summary of the workflow.
When you run the experiment, the following output will appear:
| | Name | Entity-Type | JobID | RunID | Time | Status | Returncode |
|----|----------------|---------------|-------------|---------|---------|-----------|--------------|
| 0 | hello_world | Model | 1778304.4 | 0 | 10.0657 | Completed | 0 |
| 1 | orchestrator_0 | DBNode | 1778304.3+2 | 0 | 43.4797 | Cancelled | 0 |
Note
Failure to tear down the Orchestrator at the end of an Experiment
may lead to Orchestrator launch failures if another Experiment is
started on the same node.